| | | | Together with | | |  |
|
|
|
|
|
| | Midjourney 成立醫療部門並推出水下超音波全身掃描儀,只要 60 秒就能產出媲美 MRI 解析度的 3D 人體數據。 | 掃描過程像泡溫泉:使用者降入水池後,周圍的感測環會發射超音波,60 秒內就能收集完骨骼、肌肉與器官數據。 靠 AI 將聲波轉成 3D 影像:掃描時每秒會產生數 TB 數據,系統透過兩 Petaflops 算力和 AI 分割技術,把波形變化重建成精細的身體地圖。 先開 Spa 館避開早期監管:首家 Midjourney Spa 預計 2027 年在舊金山開幕,初期只提供不需要高階 FDA 審核的身體組成圖,以利快速進入市場。
| 醫療硬體跟 Midjourney 原本的 AI 算圖業務有什麼關係?
將聲波數據還原成 3D 影像,是一項非常吃算力的圖像重建工程,這項新業務剛好能消化 Midjourney 目前閒置的 AI 算力資源,找到新的商業用途。 |
|
|
|
|
ADVERTISING
讓 {{active_subscriber_count}}+ 位讀者認識你的產品 | 《Brief AI 電子報》讀者近 50% 擁有碩士以上學歷、管理階層超過 40%。超過 30 家國內外知名品牌合作,例如:Intel、數位時代、知識衛星... | 看看合作方式 |
|
|
|
| | Claude Code 現在會把你的對話過程直接變成一個會自動更新的網頁,讓你用內部連結分享給團隊。 | 畫面會跟著進度自動刷新:當你繼續跟 Claude Code 處理工作時,大家看到的網頁內容都會同步更新到最新狀態。 直接整合你手邊的資源:產出來的網頁不是憑空生成的,它是直接抓你現有的程式碼、外掛、串接工具的資料來排版。 只有團隊方案能用:目前是 beta 版,開放給 Team、Enterprise 方案,分享範圍也被嚴格限制在公司內部。
| 我做出來的 Artifacts 誰看得到?
預設只有你自己看得到,即使你把連結分享出去,也只有經過驗證的公司內部成員打得開,沒辦法公開到外面。 |
|
|
|
| 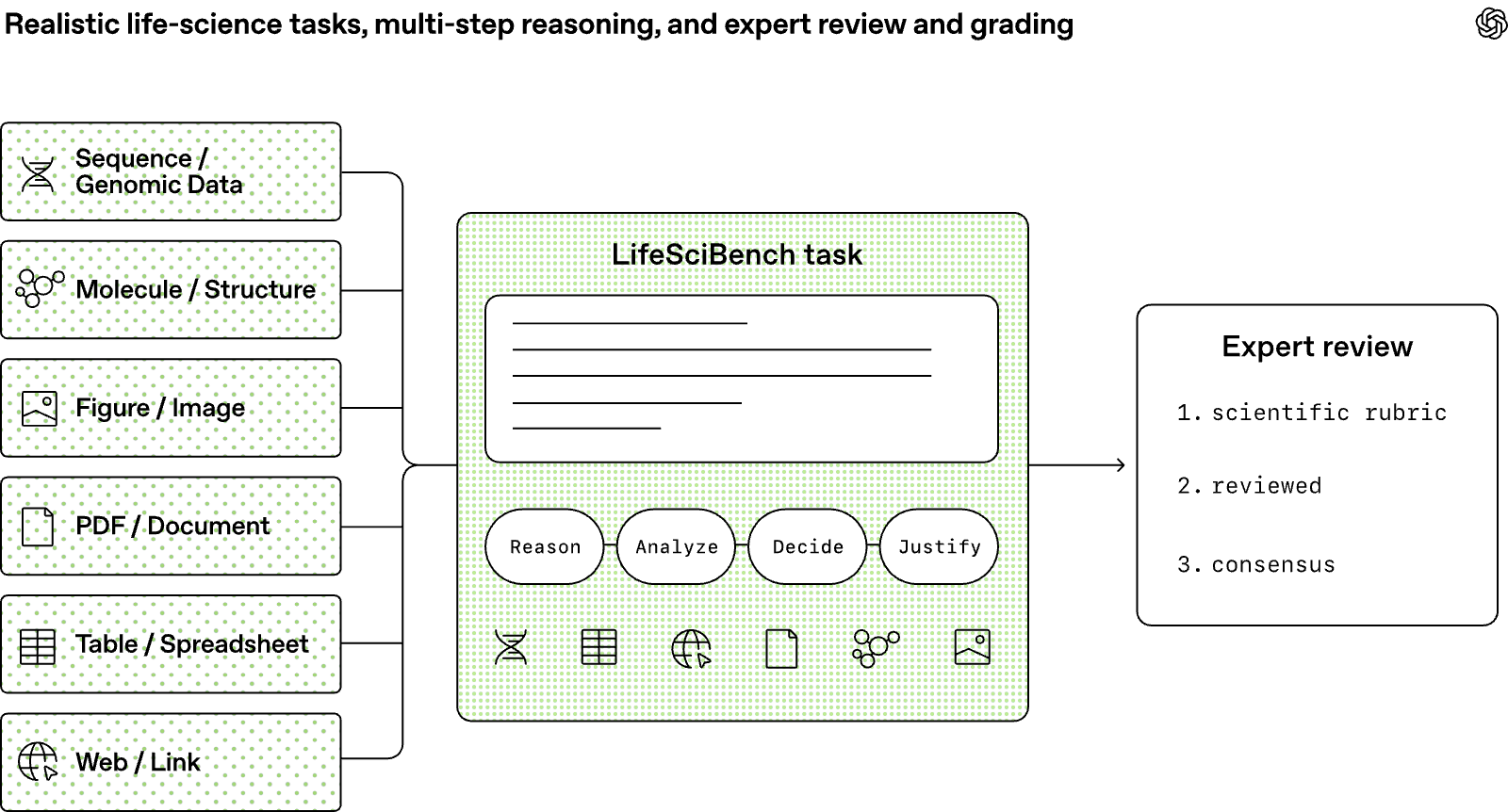 | OpenAI 推出由 173 位科學家共同開發的 LifeSciBench 評測,用 750 個真實研究任務取代一般的知識問答,直接測試 AI 處理不完整證據、圖表、做科學決策的能力。 | 考驗真實決策而不是單純測知識:範圍包含實驗設計、資料分析、轉譯醫學等七大工作流程,要求 AI 在充滿不確定和真實條件限制下,給出有根據的判斷。 最新模型在科學溝通進步最多:GPT-Rosalind 的整體任務通過率來到 36.1%,明顯比 GPT-5.5 更好,但在需要精確產出序列或分子結構的任務上還是偏弱。 複雜圖表和附件是目前最大瓶頸:當研究任務有附圖表、PDF、序列檔時,最強模型的通過率會從純文字的 44.5%直接掉到 28.6%。
| 整體通過率不到四成,這代表現在的 AI 模型對真實的生命科學研究還沒有實用價值嗎?
其實不是,很多生命科學任務本來就不能只看最後答案給分。在大約 14% 沒通過的任務裡,模型其實已經拿到超過一半的部分給分,這代表 AI 通常找得到正確證據,也能完成部分推論,但常常因為漏掉關鍵限制、看錯資料,或是沒有連到最終的實務決策,才達不到科學界要求的高標準。 |
|
|
|
| | OpenAI 的 o3 Deep Research 協助波士頓兒童醫院、哈佛大學,重新分析 376 個一直找不出病因的兒科罕病舊案,最後成功幫 18 個案例找到確診答案。 | 幫專家加速整理證據:AI 把病人的臨床特徵、遺傳模式、科學文獻連結起來,省下大量處理複雜資訊的時間。 讓大規模重啟舊案變可能:醫學知識一直更新,AI 讓專家有辦法回頭重新檢查以前的案子,找出新的線索。 找出的病因涵蓋多個領域:這次確診的案例包含了神經發育障礙、罕見神經肌肉疾病、兒科猝死、早發性精神病。
| 所以這些診斷是 AI 直接判定的嗎?
不是,AI 沒有對病人下診斷或是做任何醫療決定。它只負責整理出有證據支持的假設,所有結果最後都還要經過人類專家親自審查、臨床檢驗來確認。 |
|
|
|
|  | Meta 強制把核心團隊裡 30% 到 50%的軟體工程師調到一個新部門,每天的工作就是幫 AI 寫出的 GitHub 專案給人類回饋。 | 高階人才被抓去做重複性工作:大約有 4500 名軟體工程師現在被調到 Agent Data Optimization 部門,每天都在看 AI 寫的程式碼並給評價。 基礎架構團隊被掏空:把資安團隊的資深人才調走,直接導致 Instagram 發生嚴重的資安漏洞事件,駭客利用零認證密碼重置漏洞直接盜用帳號。 Meta 照抄 Scale AI 的做法:高層為了優先推動大量的人類回饋強化學習(RLHF)來訓練還沒推出的寫程式 AI 模型,寧願犧牲現有核心平台的穩定性。
| 為什麼 Meta 不把資料標註外包出去,而是要叫核心的軟體工程師來做?
因為這種 AI 訓練需要很深的技術底子,工程師必須自己設計出寫程式的任務、寫測試來驗證結果、把所有東西包進 Docker 容器,還要負責評估好幾個 AI 模型寫出來的程式碼。 |
|
|
|